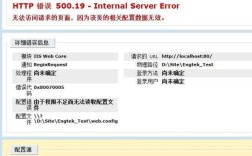
服务器无法在此时接受控制信息”这一错误提示通常出现在服务器管理、远程连接或自动化运维场景中,表明当前服务器因某种原因处于非正常状态,无法接收来自客户端或管理工具的控制指令,这一问题的成因复杂,可能涉及服务器负载、资源限制、网络状态、软件配置或外部攻击等多个维度,以下从可能原因、排查步骤、解决方案及预防措施等方面展开详细分析,并结合实际场景提供应对策略。

(图片来源网络,侵删)
问题成因分析
服务器无法接受控制信息的直接原因是其控制接口(如SSH、RDP、API端口等)处于不可用状态,具体可归纳为以下几类:
资源耗尽型问题
服务器资源(CPU、内存、磁盘I/O、网络带宽)达到上限时,可能导致控制服务进程无响应或拒绝连接。
- CPU 100%占用:恶意挖矿程序、死循环进程或高并发请求会抢占计算资源,导致系统进程调度异常。
- 内存溢出:应用程序内存泄漏或瞬间流量激增可能导致OOM(Out of Memory),触发系统强制终止进程。
- 磁盘空间不足:日志文件堆积或数据库膨胀可能使磁盘写满,影响系统服务运行。
服务配置或故障
- 控制服务未启动:如SSH、WinRM等服务未运行或被禁用。
- 端口冲突或防火墙拦截:控制端口被其他进程占用,或防火墙规则误封。
- 服务崩溃:依赖的底层服务(如systemd、supervisord)异常导致控制进程退出。
网络层面问题
- 网络连接中断:服务器与客户端之间的网络链路故障,如交换机宕机、路由策略变更。
- DDoS攻击:恶意流量占满带宽或连接数,导致正常控制请求被丢弃。
- 负载过高:长连接未及时释放,达到最大连接数限制(如
MaxStartups配置不当)。
系统或软件异常
- 内核级故障:驱动不兼容或系统更新导致内核 panic。
- 依赖库损坏:控制服务依赖的动态链接库文件丢失或版本不匹配。
- 安全策略限制:SELinux、AppArmor等安全模块拦截了控制指令。
人为操作失误
- 误执行命令:如
iptables -F清空防火墙规则,或误杀关键进程。 - 配置错误:修改了SSH配置文件中的
PermitRootLogin或PasswordAuthentication导致无法登录。
排查步骤
定位问题时需遵循“从外到内、从简到繁”的原则,结合日志和工具逐步缩小范围:
初步检查
- 确认服务状态:通过本地控制台或串口登录服务器,检查控制服务是否运行:
systemctl status sshd # Linux Get-Service -Name WinRM # Windows
- 查看资源使用率:使用
top、htop或Task Manager监控CPU、内存占用。 - 检查网络连通性:通过
ping、telnet测试端口可达性,如telnet 192.168.1.100 22。
日志分析
- 系统日志:Linux下查看
/var/log/messages、/var/log/syslog,Windows检查“事件查看器”。 - 应用日志:如SSH日志
/var/log/auth.log(登录失败记录)、Web服务器错误日志。 - 内核日志:
dmesg | tail查看硬件或驱动相关报错。
工具诊断
- 网络诊断:使用
netstat -anpt检查端口监听状态,tcpdump抓包分析异常流量。 - 进程分析:通过
ps auxf查看进程树,lsof -i:22定位占用端口的进程。 - 系统调用跟踪:
strace -p <PID>跟踪系统调用,定位阻塞点。
模拟复现
- 在客户端尝试复现问题,如使用
ssh -v查看详细连接过程,或通过Wireshark抓包对比正常与异常请求的差异。
解决方案与修复
根据排查结果,针对性采取修复措施:

(图片来源网络,侵删)
资源耗尽类
- 清理资源:终止异常进程(
kill -9 <PID>),清理临时文件(rm -rf /tmp/*)。 - 扩容或优化:增加服务器配置,或优化应用程序代码减少资源占用。
- 限制资源使用:通过
cgroups或ulimit限制进程资源。
服务配置类
- 重启服务:
systemctl restart sshd或service sshd restart。 - 修改配置:编辑
/etc/ssh/sshd_config,调整参数后重载配置(systemctl reload sshd)。 - 检查防火墙:允许控制端口通过,如
iptables -A INPUT -p tcp --dport 22 -j ACCEPT。
网络问题类
- 重置网络:Linux下
ifdown eth0 && ifup eth0,Windows重启网络适配器。 - 防御DDoS:配置防火墙规则(如
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT),或使用WAF防护。
系统异常类
- 修复依赖:使用
yum reinstall或sfc /scannow修复损坏的系统文件。 - 回滚配置:恢复备份的配置文件或系统快照。
安全策略类
- 临时关闭SELinux:
setenforce 0,若解决问题则调整策略。 - 审计规则:通过
ausearch -ts recent查看安全模块拦截日志。
预防措施
为避免问题复发,需从架构和运维层面加强防护:
| 预防措施 | 具体操作 |
|---|---|
| 监控告警 | 部署Zabbix、Prometheus等工具,监控资源使用率和服务状态,设置阈值告警。 |
| 访问控制 | 使用堡垒机或VPN限制管理入口,启用双因素认证(如SSH密钥+密码)。 |
| 定期维护 | 定期清理日志、更新系统补丁,避免历史漏洞引发异常。 |
| 灾备演练 | 定期测试备份恢复流程,确保故障时快速切换。 |
| 架构优化 | 采用负载均衡分散压力,避免单点故障;微服务化降低系统耦合度。 |
相关问答FAQs
Q1:服务器提示“无法接受控制信息”后,如何紧急恢复访问?
A:首先尝试通过本地控制台或IPMI/KVM远程登录,若无法登录,检查物理连接(电源、网线),或通过救援模式(如Linux Live CD)挂载磁盘修复配置,若为资源耗尽,强制终止高负载进程后重启服务。
Q2:如何避免SSH服务频繁出现“无法接受连接”问题?
A:优化SSH配置,如调整MaxStartups(默认10:30:100)限制并发连接数;使用AllowUsers白名单限制登录用户;部署fail2ban封禁异常IP;定期检查/var/log/auth.log排查暴力破解风险。

(图片来源网络,侵删)